Decision trees can operate with non-numerical data.
Building a decision tree amounts to deciding the order in which the decisions should be made.
Surprise inversely related to probability:
\[ s(x) = \log \Bigg\lparen\frac{1}{p(x)}\Bigg\rparen \]
Writing like this has a few useful benefits:
The surprise of a sequence of events is the sum of the surprise for each individual event:
\[ s(a,a,b) = s(a) + s(a) + s(b) \]
The above video explains:
\[ \text{Entropy} = \sum_{i = 0}^n p(x_i) \log_2 \Bigg\lparen\frac{1}{p(x)}\Bigg\rparen \]
\[ \text{Entropy} = -\sum_{i = 0}^n p(x_i) \log_2 \Big(p(x_i)\Big) \]
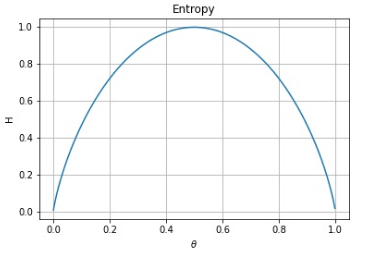
Say we have a random binary variable \(x \in \{\text{Heads},\text{Tails}\}\), and \(\theta\) is the probability \(p(x = \text{Heads})\). The entropy \(H\) can be plotted as follows:
You can see that entropy reduces as the probability approaches 0 and 1. That is to say, if we are more certain that a particular outcome will happen, entropy decreases.
When building a decision tree, we want the next decision to have a large impact on the entropy towards 0. The Information gain tells us how important a given attribute \(x_i\) is. It is used to decide the order in which to place an attribute.
Information Gain \(G(S,F)\) is defined as follows, where \(S\) is the set of elements and \(F\) is the set of features:
\[ G(S,F) = \text{Entropy}(S) - \sum_{f \in F} \frac{|S_f|}{|S|} \text{Entropy}(S_f) \]
Information Gain should be as high as possible over a decision tree.
Computes the information gain for every possible feature in the set \(F\) and chooses the one that produces the highest value, outputting a complete decision tree.